什么是延迟加载?
resultMap可以实现高级映射,association,collection具有延迟加载的功能。
当我们需要查询某个信息的时候,再去查询,达到按需查询,就是延迟加载
可以大大提高数据库的性能
那么我们代码撸起来把:
延迟加载我们首先要在全局配置文件中开启:
SQlMapConfig.xml:
lazyLoadingEnabled:全局性设置懒加载。如果设为‘false’,则所有相关联的都会被初始化加载。
aggressiveLazyLoading:当设置为‘true’的时候,懒加载的对象可能被任何懒属性全部加载。否则,每个属性都按需加载。
其次是OrderMapperCustomer.xml映射文件:
测试文件:
//延迟加载 @Test public void testfindSlowing() throws Exception { SqlSession sqlSession = getSqlSessionFactory().openSession(); //代理对象 OrderMapperCustomer mapper = sqlSession.getMapper(OrderMapperCustomer.class); //测试findOrderUsers List orders = mapper.findSlowing(); for(Orders order : orders){ User user = order.getUser(); System.out.println(user); } sqlSession.close(); } 结果:
DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@8e24743]DEBUG [main] - ==> Preparing: SELECT * from ordersDEBUG [main] - ==> Parameters:DEBUG [main] - <== Total: 3DEBUG [main] - ==> Preparing: select * from user where id=?DEBUG [main] - ==> Parameters: 1(Integer)DEBUG [main] - <== Total: 1User [id=1, username=王五, birthday=null, sex=2, address=null]User [id=1, username=王五, birthday=null, sex=2, address=null]DEBUG [main] - ==> Preparing: select * from user where id=?DEBUG [main] - ==> Parameters: 10(Integer)DEBUG [main] - <== Total: 1User [id=10, username=张三, birthday=Thu Jul 10 00:00:00 CST 2014, sex=1, address=北京市]DEBUG [main] - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@8e24743]
缓存:
用于减轻数据库压力,提高数据库的性能
mybatis提供一级缓存&二级缓存
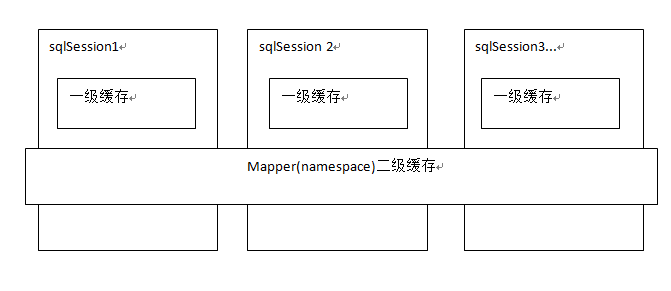
在操作数据库时需构造sqlsession对象,在对象中有一个数据结构(HashMap)用于存储数据
不同的sqlsession之间的缓存数据区域时互不影响的
一级缓存:是sqlsession级别的缓存
二级缓存:是mapper级别的缓存多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
为什么需要缓存:
如果缓存中有数据就不需要从数据库中获取,提高系统性能。
一级缓存:
工作原理:

第一次查询先去缓存中查询,若没有则取数据库中查询
如果sqlsession去执行commit操作(插入,删除,更新),清空sqlsession中的一级缓存,使存储区域得到最新的
信息,避免脏读。
第二次在查询第一次数据,首先在缓存中查找,找到了则不再去数据库想查询
默认支持一级缓存,不需要手动去开启。
测试代码:
在testUserMapper.java
//一级缓存 @Test public void testCahseFiret() throws Exception{ SqlSession sqlSession = getSqlSessionFactory().openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); //第一次查询 User user = mapper.findUserById(1); System.out.println(user); //第二次查询 User user1 = mapper.findUserById(1); System.out.println(user1); sqlsession.close(); } 结果:
由此可见,查询时,只查询了一次
DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@8e24743]DEBUG [main] - ==> Preparing: select * from user where id=?DEBUG [main] - ==> Parameters: 1(Integer)DEBUG [main] - <== Total: 1User [id=1, username=王五, birthday=null, sex=2, address=null]User [id=1, username=王五, birthday=null, sex=2, address=null]
有清空操作:
@Test public void testCahseFiret() throws Exception{ SqlSession sqlSession = getSqlSessionFactory().openSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); //第一次查询 User user = mapper.findUserById(1); System.out.println(user); //commit User adduser = new User(); adduser.setUsername("Mr"); adduser.setSex(1); mapper.addUser(user); //清空缓存 sqlSession.commit(); //第二次查询 User user1 = mapper.findUserById(1); System.out.println(user1); sqlSession.close(); } 结果:
DEBUG [main] - Opening JDBC ConnectionDEBUG [main] - Created connection 149047107.DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@8e24743]DEBUG [main] - ==> Preparing: select * from user where id=?DEBUG [main] - ==> Parameters: 1(Integer)DEBUG [main] - <== Total: 1User [id=1, username=王五, birthday=null, sex=2, address=null]DEBUG [main] - ==> Preparing: insert into user(id,username,birthday,sex,address) value(?,?,?,?,?)DEBUG [main] - ==> Parameters: 1(Integer), 王五(String), null, 2(Integer), null
一级缓存的应用:
正式开发,是将mybatis和spring进行整合,事物控制在service中
一个servic包括很多mapper方法调用
二级缓存:

首先开启mybatis的二级缓存。
sqlSession1去查询用户id为1的用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果SqlSession3去执行相同 mapper下sql,执行commit提交,清空该 mapper下的二级缓存区域的数据。
sqlSession2去查询用户id为1的用户信息,去缓存中找是否存在数据,如果存在直接从缓存中取出数据
。
二级缓存与一级缓存区别,二级缓存的范围更大,多个sqlSession可以共享一个UserMapper的二级缓存区域。
UserMapper有一个二级缓存区域(按namespace分) ,其它mapper也有自己的二级缓存区域(按namespace分)。
每一个namespace的mapper都有一个二缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同 的二级缓存区域中。
开启二级缓存:
cacheEnabled:对在此配置文件下的所有cache 进行全局性开/关设置。
开启mapper下的二级缓存:
UserMapper.xml
实现pojo类实现里序列化接口:
public class User implements Serializable{......} 为了将存储数据取出执行反序列化的操作,以内二级缓存存储介质多种多种杨,不一定在内存
测试类 :
//二级缓存 @Test public void testCahseSecond() throws Exception{ SqlSession sqlSession = getSqlSessionFactory().openSession(); SqlSession sqlSession1 = getSqlSessionFactory().openSession(); //第一次查询 UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.findUserById(1); System.out.println(user); //将执行关闭操作,将sqlsession写道二级缓存 sqlSession.close(); //第二次查询 UserMapper mapper2 = sqlSession1.getMapper(UserMapper.class); User user1 = mapper2.findUserById(1); System.out.println(user1); sqlSession1.close(); } 结果:
DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@1990a65e]DEBUG [main] - ==> Preparing: select * from user where id=?DEBUG [main] - ==> Parameters: 1(Integer)DEBUG [main] - <== Total: 1User [id=1, username=王五, birthday=null, sex=2, address=null]DEBUG [main] - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@1990a65e]DEBUG [main] - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@1990a65e]DEBUG [main] - Returned connection 428910174 to pool.DEBUG [main] - Cache Hit Ratio [com.MrChengs.mapper.UserMapper]: 0.0DEBUG [main] - Opening JDBC ConnectionDEBUG [main] - Created connection 1873859565.DEBUG [main] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@6fb0d3ed]DEBUG [main] - ==> Preparing: select * from user where id=?DEBUG [main] - ==> Parameters: 1(Integer)DEBUG [main] - <== Total: 1User [id=1, username=王五, birthday=null, sex=2, address=null]
一些简单的参数配置:
1.
useCache:为fasle时,禁用缓存
<select id="" useCache="true"></select>
针对每次查询都需要最新数据的sql
2.
flushCache:刷新缓存,实质就是清空缓存,刷寻缓存可以避免数据的脏读
<select id="" flushCache="true"></select>
3.
flushInterval:刷新间隔,可以设置任意的毫秒数,代表一个何况i的时间段
<cache flushInterval="" />
mybatis整合ehcache
ehcache分布式的缓存

不使用分布缓存,缓存的数据在各各服务单独存储,不方便系统 开发。所以要使用分布式缓存对缓存数据进行集中管理。
mybatis无法实现分布式缓存,需要和其它分布式缓存框架进行整合。
整和方法:
mybatis提供了cache接口,如果要实现自己的缓存逻辑,实现cache接口即可
在mybatis包里的cache类里面

二级缓存应用场景:
对于访问多的查询请求且用户对查询结果实时性要求不高,此时可采用mybatis二级缓存技术降低数据库访问量,提高访问速度,业务场景比如:耗时较高的统计分析sql、电话账单查询sql等。
实现方法如下:通过设置刷新间隔时间,由mybatis每隔一段时间自动清空缓存,根据数据变化频率设置缓存刷新间隔flushInterval,比如设置为30分钟、60分钟、24小时等,根据需求而定。
二级缓存的局限性:
mybatis二级缓存对细粒度的数据级别的缓存实现不好,比如如下需求:对商品信息进行缓存,由于商品信息查询访问量大,但是要求用户每次都能查询最新的商品信息,此时如果使用mybatis的二级缓存就无法实现当一个商品变化时只刷新该商品的缓存信息而不刷新其它商品的信息,因为mybaits的二级缓存区域以mapper为单位划分,当一个商品信息变化会将所有商品信息的缓存数据全部清空。解决此类问题需要在业务层根据需求对数据有针对性缓存。